人类记忆系统的启发
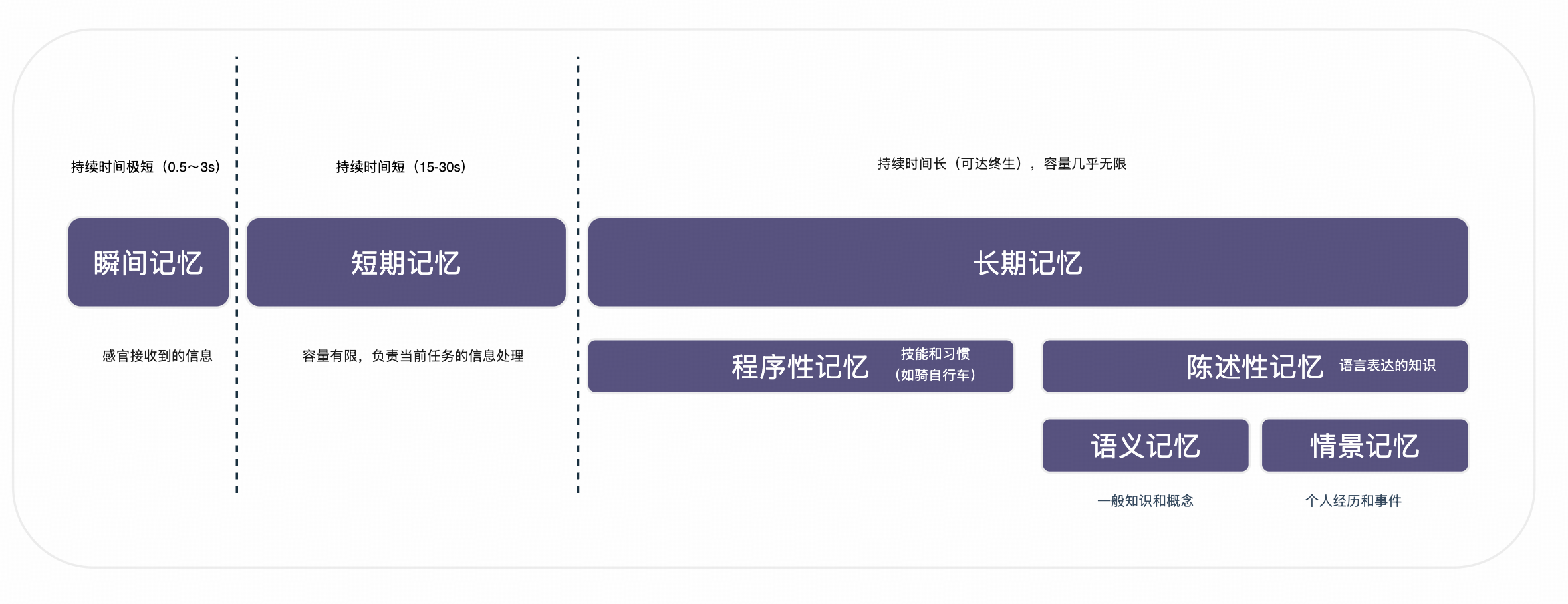
根据认知心理学的研究,人类记忆可以分为以下几个层次:
- 感觉记忆(Sensory Memory):持续时间极短(0.5-3秒),容量巨大,负责暂时保存感官接收到的所有信息
- 工作记忆(Working Memory):持续时间短(15-30秒),容量有限(7±2个项目),负责当前任务的信息处理
- 长期记忆(Long-term Memory):持续时间长(可达终生),容量几乎无限,进一步分为:
- 程序性记忆:技能和习惯(如骑自行车)
- 陈述性记忆:可以用语言表达的知识,又分为:
- 语义记忆:一般知识和概念(如"巴黎是法国首都")
- 情景记忆:个人经历和事件(如"昨天的会议内容")
为何智能体需要记忆与RAG
人类智能的一个重要特征就是能够记住过去的经历,从中学习,并将这些经验应用到新的情况中。 对于基于LLM的智能体而言,通常面临两个根本性局限:对话状态的遗忘和内置知识的局限。
(1)局限一:无状态导致的对话遗忘
当前的大语言模型虽然强大,但设计上是无状态的。这意味着,每一次用户请求(或API调用)都是一次独立的、无关联的计算。模型本身不会自动“记住”上一次对话的内容。
问题:
- 上下文丢失:在长对话中,早期的重要信息可能会因为上下文窗口限制而丢失
- 个性化缺失:Agent无法记住用户的偏好、习惯或特定需求
- 学习能力受限:无法从过往的成功或失败经验中学习改进
- 一致性问题:在多轮对话中可能出现前后矛盾的回答
要解决这个问题,我们的框架需要引入记忆系统。
(2)局限二:模型内置知识的局限性
LLM 的另一个核心局限在于其知识是静态的、有限的。这些知识完全来自于它的训练数据,并因此带来一系列问题:
问题:
- 知识时效性:大模型的训练数据有时间截止点,无法获取最新信息
- 专业领域知识:通用模型在特定领域的深度知识可能不足
- 事实准确性:通过检索验证,减少模型的幻觉问题
- 可解释性:提供信息来源,增强回答的可信度
RAG技术应运而生。它的核心思想是在模型生成回答之前,先从一个外部知识库(如文档、数据库、API)中检索出最相关的信息,并将这些信息作为上下文一同提供给模型。
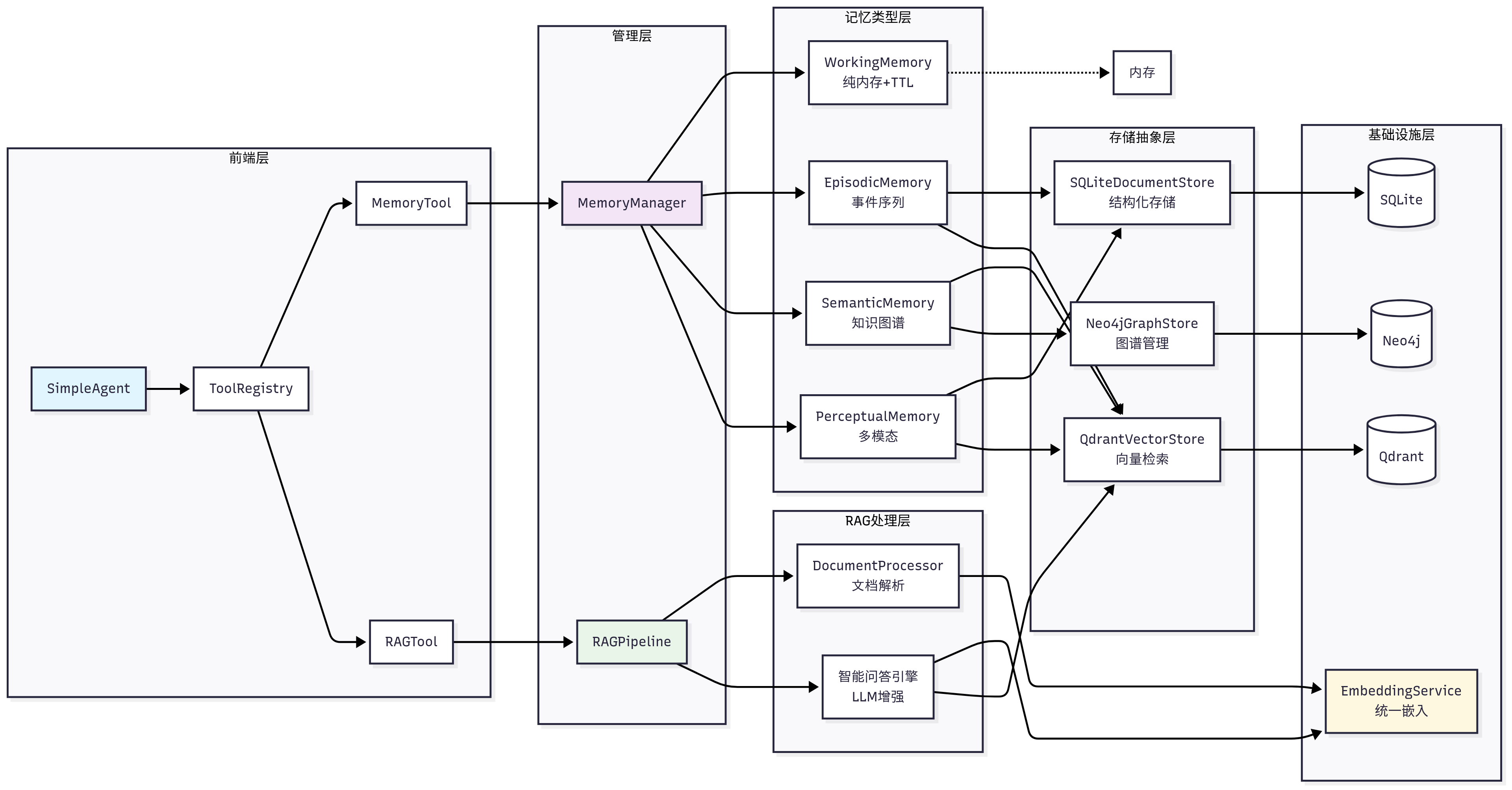
记忆与RAG系统架构设计
想法或问题?在 GitHub Issue 下方参与讨论
去评论