一、微调(Fine-tuning)的原理
1. 什么是微调
微调就是:
在已经训练好的大模型(比如 Qwen1-5B/8B)基础上,针对你的特定任务再训练,让模型学会你的“偏好”或“专用知识”。
类比:
- 大模型 = 一个通用的知识大脑(懂很多东西,但很笼统)
- 微调 = 在这个大脑上做“专项训练”,让它擅长你关心的领域(比如甄嬛聊天风格)
2. 为什么要微调
- 大模型很大:训练成本高,普通人无法从零训练。
- 直接用大模型:模型可能回答通用,但不符合你的风格或任务。
- 微调:只改变部分参数(LoRA)就能适配任务,不会更新原模型的所有权重,成本低、速度快。
3. 微调原理细节
大模型有大量参数(比如 80 亿个参数):
- 全量微调:修改模型所有参数(消耗大、容易过拟合)
- LoRA 微调:只修改部分矩阵的低秩参数(低成本、高效)
大模型里的一个线性层原来是:$$y = Wx$$ LoRA 方法是:$$y = Wx + BAx$$
其中: W 不变(老师原有知识) A、B 是新增的小矩阵(老师的小笔记本) 你只训练 A 和 B(非常省显存) 这就相当于: 主大脑(W)不改 学新技能用“外挂笔记”(BA)
LoRA:
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=[ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj" ],
r=8,
lora_alpha=16,
lora_dropout=0.05,
)
target_modules:只微调这些矩阵r:低秩矩阵的秩(参数量大小)lora_alpha:缩放系数lora_dropout:训练中随机丢弃部分 LoRA 参数,防止过拟合
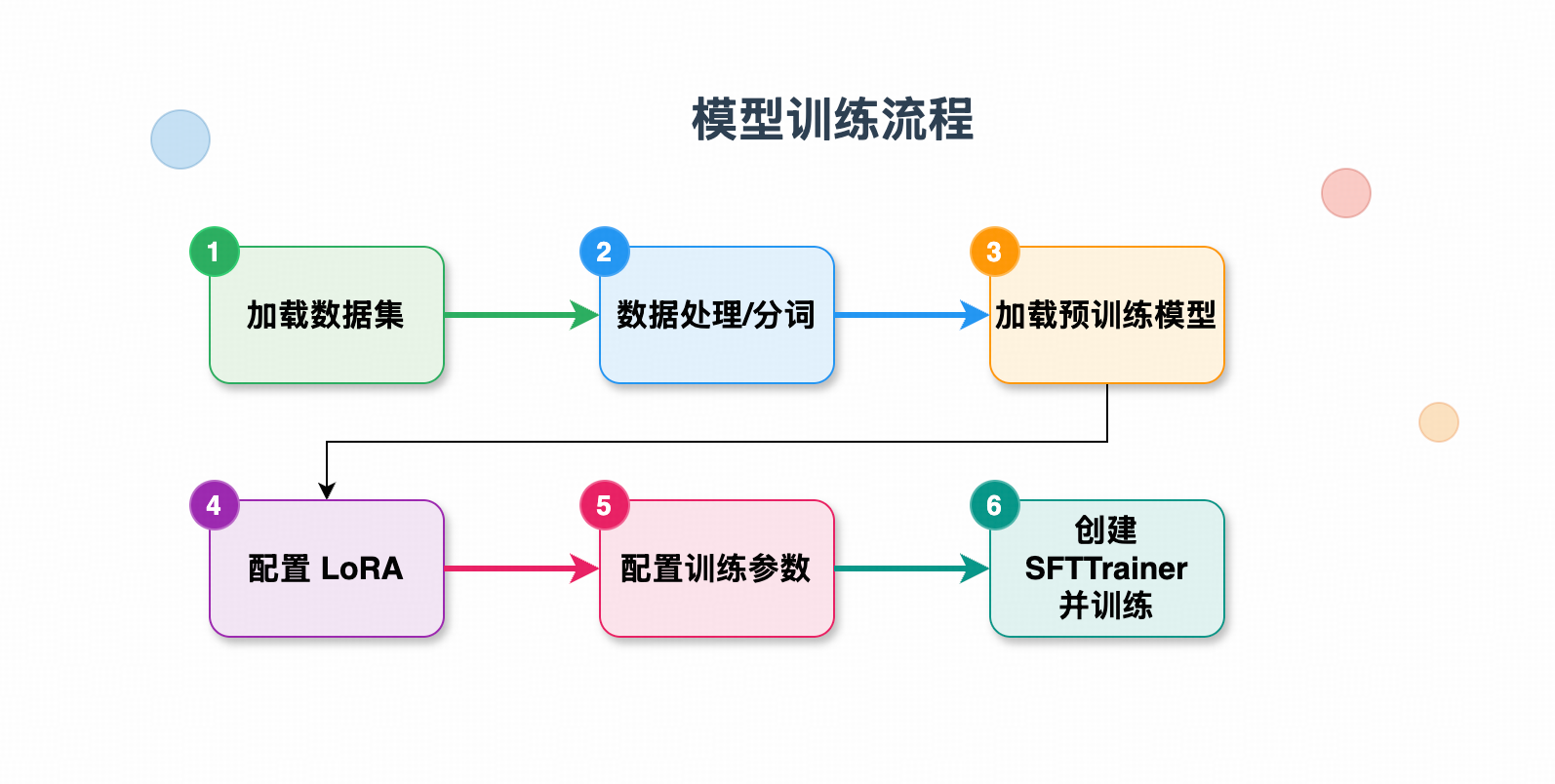
4. 微调步骤
-
准备数据 你的 JSON 数据,每条包含:
instruction(用户问题)input(可选上下文)output(模型应答)
-
数据处理(tokenizer) 模型只能处理数字(token),所以要把文本转成
input_ids和attention_mask:pythonencodings = tokenizer(text, truncation=True, max_length=512) example["input_ids"] = encodings["input_ids"] example["attention_mask"] = encodings["attention_mask"] -
定义 LoRA 配置 告诉模型只微调哪些参数。
-
定义训练参数(
TrainingArguments)per_device_train_batch_size:一次喂多少条数据gradient_accumulation_steps:梯度累积(一次更新前累积多少步)learning_rate:学习率num_train_epochs:训练轮次fp16/bf16:混合精度(CPU 上关闭)
-
训练(SFTTrainer) 把模型、数据、训练参数、LoRA 配置交给
SFTTrainer,调用.train()就开始训练。 -
保存模型 训练完成后保存:
pythontrainer.save_model("./qwen-huanhuan-lora/final")
二、代码里 API 的作用
| API / 类 | 功能 |
|---|---|
AutoTokenizer.from_pretrained(model_id) | 加载模型的分词器,把文字变成数字序列(token) |
AutoModelForCausalLM.from_pretrained(model_id) | 加载预训练的大语言模型 |
LoraConfig | 配置 LoRA 微调参数(只修改部分矩阵) |
SFTTrainer | 封装训练逻辑,包括前向传播、反向传播、梯度更新 |
TrainingArguments | 训练参数,控制训练细节(batch、lr、轮次等) |
Dataset.from_pandas(df) | 把 pandas 数据转换成 HuggingFace 数据集格式 |
tokenizer(...) | 将文本转成模型能理解的 token ID,并生成 attention mask |
dataset.map(preprocess) | 对每条数据应用 preprocess 函数,把文本转换成 input_ids |
2.1 专业名词
- 前向传播
意思:把输入数据“喂给模型”,让模型算出预测结果。 类比:你在做一道题,先写出你的答案。
- 后向传播
意思:计算模型预测结果和真实答案的差距,然后算出每个参数对这个差距的贡献。 类比:你检查答案错了多少,并想:“哪些步骤做错了?怎么改?”
- 梯度更新
意思:用反向传播算出来的梯度,调整模型参数,让模型更准确。 类比:你根据检查的错误修改解题方法,下次做题更对。
2.2 CPU 微调注意事项
- 模型大(1B+)在 CPU 上微调很慢
- 要关闭
fp16/bf16 - LoRA 微调可以大幅降低显存和计算需求
- 对于小模型(0.5B ~ 1.8B)在 CPU 上才比较可行
2.3 总结流程
原始文本 -> tokenizer -> input_ids -> SFTTrainer(模型+LoRA+训练参数+数据) -> train -> 保存模型
微调实质就是在已有大模型上,对特定任务的数据做梯度更新,只改一小部分参数。
二、实战展示
数据集准备
模型微调
attention_mask
attention_mask 是 Transformer 模型(如 BERT、GPT 系列)中非常重要的一个张量,用来 告诉模型哪些 token 需要注意,哪些 token 是填充(padding)无需关注的。
在 NLP 模型中,为了让批量训练更高效,通常需要 把句子补齐到相同长度,这时就会产生 padding token。如果模型把 padding token 当作有效信息,会影响输出结果。 attention_mask 就是用来标记这些 padding token 的。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokens = tokenizer(["Hello world!", "Hi"], padding=True, return_tensors="pt")
print(tokens["input_ids"])
print(tokens["attention_mask"])
输出可能是:
input_ids:
tensor([[15496, 995, 0], # 0 是 padding
[ 72, 0, 0]])
attention_mask:
tensor([[1, 1, 0],
[1, 0, 0]])
解释:
- 第一句 "Hello world!" 长度 2,补了一个 padding → attention_mask = [1,1,0]
- 第二句 "Hi" 长度 1,补了两个 padding → attention_mask = [1,0,0]
模型在计算 self-attention 时会 忽略 padding 的位置。
代码
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model, TaskType
import pandas as pd
from datasets import Dataset
from trl import SFTTrainer
from transformers import TrainingArguments
device = "cpu"
print(f"Using device: {device}")
# 你当前环境不能加载 8B!只能换成小的 (1.8B 或 0.5B)
model_id = "./qw-chat05/Qwen/Qwen2___5-0___5B";
df = pd.read_json('../../dataset/huanhuan.json')
ds = Dataset.from_pandas(df)
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# CPU 模式:必须 float32
model = AutoModelForCausalLM.from_pretrained(
model_id,
dtype=torch.float32,
device_map={"": "cpu"},
trust_remote_code=True
)
def build_text(example):
messages = [
{"role": "system", "content": "现在你要扮演皇帝身边的女人--甄嬛"},
{"role": "user", "content": example["instruction"] + example["input"]},
{"role": "assistant", "content": example["output"]},
]
example["text"] = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False
)
return example
ds = ds.map(build_text)
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
r=8,
lora_alpha=16,
lora_dropout=0.05,
)
# ------------------------------------------------------
# 5. 训练参数
# ------------------------------------------------------
training_args = TrainingArguments(
output_dir="./qwen-huanhuan-lora",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
learning_rate=2e-4,
num_train_epochs=3,
logging_steps=5,
save_strategy="epoch",
fp16=False,
bf16=False,
)
# ------------------------------------------------------
# 6. SFTTrainer(注意:TRL 0.26 不接受 formatting_func)
# ------------------------------------------------------
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=ds,
peft_config=peft_config,
)
trainer.train()
trainer.save_model("./qwen-huanhuan-lora2/final")
模型推理
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# 强制使用 CPU(避免 MPS 兼容性问题)
device = "cpu"
print(f"Using device: {device}")
model_id = "./qw-chat05/Qwen/Qwen2___5-0___5B";
lora_path = "./qwen-huanhuan-lora/final"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
base_model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map={"": device},
trust_remote_code=True
)
# 加载 LoRA 权重
model = PeftModel.from_pretrained(base_model, lora_path, device_map={"": device})
# 推理示例
questions = ['你是谁,你生日是哪一天']
for q in questions:
inputs = tokenizer.apply_chat_template([
{"role": "user", "content": q}
], return_tensors="pt", return_dict=True)
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(**inputs, max_new_tokens=128, do_sample=True,
top_p=0.9)
print(tokenizer.decode(outputs[0]))
日志
{'loss': 3.06, 'grad_norm': 1.6156032085418701, 'learning_rate': 9.336188436830836e-05, 'entropy': 3.06442369222641, 'num_tokens': 137673.0, 'mean_token_accuracy': 0.5385425604879857, 'epoch': 0.54}
这条日志:
训练还不到一轮(epoch 0.54) 当前 loss = 3.06,还在下降阶段 梯度正常(grad_norm ≈ 1.6) 学习率约 0.000093 模型 token-level 正确率 ≈ 53.85%,还有提升空间