!!!tip 本文探讨了检索增强生成(RAG)技术,涵盖了其在自然语言处理中的应用、工作原理、优势,以及与之相关的知识向量化、知识召回、向量数据库、向量模型和 prompt 提示词等方面的内容。 !!!
RAG
在自然语言处理领域,大型语言模型(LLM)如GPT-4o等已经取得了显著的进展,它们能够生成连贯、自然的文本,回答问题,并执行其他复杂的语言任务。然而,这些模型存在一些固有的局限性,如 ="模型幻觉问题"、"时效性问题"和"数据安全问题"=。
大模型问题
幻觉问题
是指在生成文本时,模型输出的信息看似合理或真实,但实际上是不准确的、虚构的或没有事实依据的。这种现象通常发生在模型未能获取到足够相关的数据,或者在理解上下文时出现偏差,导致它生成的内容并不与现实或事实相符。
时效性问题
- 过时的信息:例如,模型无法回答最新的新闻、科技进展或社会变化,因为它所依赖的知识库没有涵盖这些信息。
- 无法处理动态数据:模型难以处理需要实时更新的领域,如股票市场、天气预报、体育赛事等。
数据安全问题
攻击者可能通过操控模型输入(例如通过“提示注入”攻击),诱导模型生成包含敏感信息的内容,或进行恶意利用。
为了弥补 AI 模型自身知识的不足,我们可以为它提供外部知识的支持,就像给学生提供参考书和工具书一样,帮助他们更好地理解和解决问题。检索增强生成 (RAG) 技术就是一种为 AI 模型提供“知识外挂”的方法。 我们可以将 RAG 技术的工作原理概括为以下几个步骤:
RAG步骤
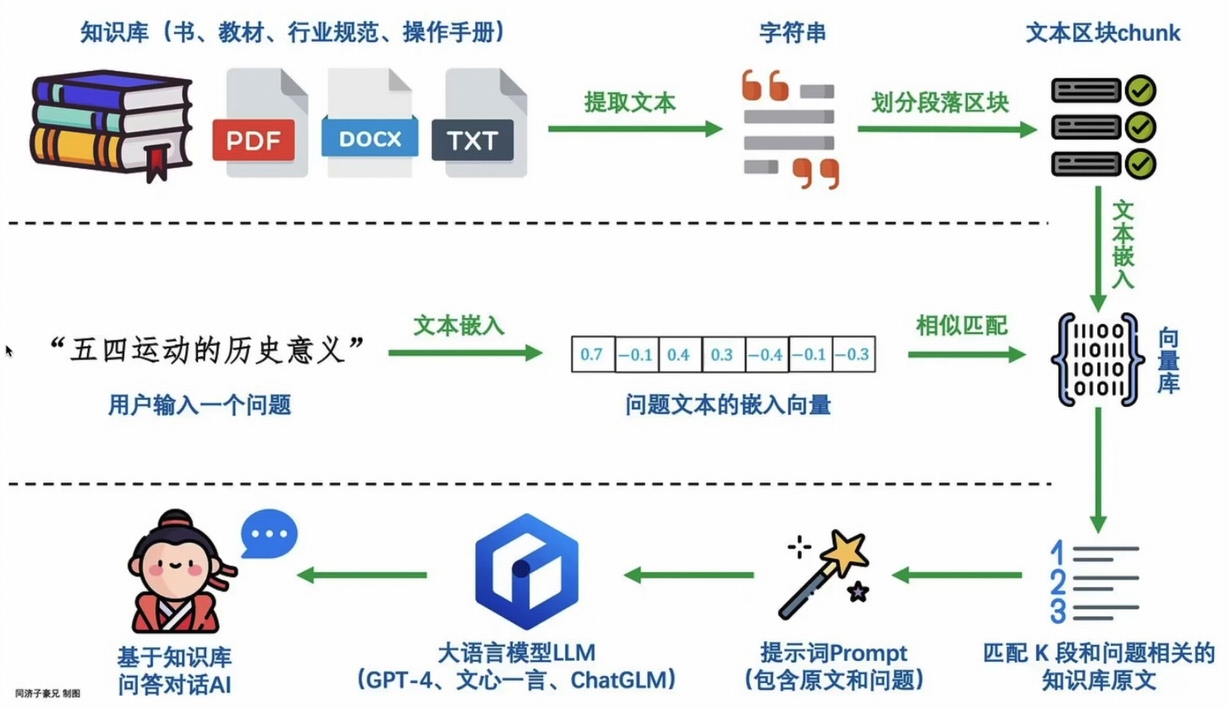
检索
是根据用户的查询内容,从外部知识库获取相关信息。具体而言,将用户的查询通过Embedding嵌入模型转换为向量,以便与向量数据库中存储的相关知识进行比对。通过相似性搜索,找出与查询最匹配的前 K 个数据。
增强
将用户的查询内容和检索到的相关知识一起嵌入到一个预设的提示词模板中
生成
将经过检索增强的提示词内容输入到大型语言模型中,以生成所需的输出。
RAG 技术的优势
RAG 技术的优势在于能够将 AI 模型与外部知识库连接起来,从而扩展 AI 模型的知识范围,提高其回答问题和生成内容的准确性。例如,在医疗领域,RAG 技术可以帮助医疗 AI 助手获取最新的医学知识和临床案例,从而提高其诊断和治疗建议的准确性。
提高准确性
通过检索外部知识库,避免了幻觉问题的困扰。相较于单纯依赖大型语言模型对海量文本数据的学习,RAG允许模型在生成文本时从事实丰富的外部知识库中检索相关信息。
时效性
RAG技术的时效性优势使其在处理实效"较强的问题时更为可靠。通过与外部知识库的连接,RAG确保了模型可以获取最新的信息,及时适应当前的事件和知识。
适应性强
与传统的知识库问答(KBQA)相比,RAG技术在知识检索方面更加灵活,不仅能够从结构化的知识库中检索信息,还能够应对非结构化的自然语言文本。
KBQA: 检索知识库,回答问题
prompt提示词
为啥需要提示词呢?不能直接讲知识+问题直接抛给大模型? 这样可能会出现的问题:
- 回答长度和风格不受控制:大模型可能生成过长或不符合预期风格的回答。
- 敏感话题的处理不受约束:没有明确的提示词可能导致模型在敏感话题上生成不适当的内容。
- 回答缺乏明确主体:没有明确的步骤告诉大模型咋做,模型生成的内容可能散乱,无法聚焦在问题的核心主题上。
- 不同场景需要针对性回答:例如,在疾病咨询或产品介绍、制定健康计划等场景下,往往需要大模型承担不同的角色,提供专业性强且符合特定领域的回答。
- 准确性不够:对于逻辑性比较强的工作,没有提示词的话,大模型可能会出错。
如何写好一个好的提示词呢
https://waytoagi.feishu.cn/wiki/EGU4wV4q6i6vprk5A7dckaGTne0
- 指定角色:让大模型承担特定角色,如营养师、意图分析师、文章扩写专家等,以确保回答符合场景需求。
- 使用分隔符清晰的表示输入的不同部分:对于复杂的任务,消除细节的歧义比较重要,使用分隔符明确告诉大模型划分的部分,不要让gpt花费精力去理解你到底在干什么。
- 明确任务步骤:提示词应清楚地指明模型需要完成哪些步骤。
- 增加示例:对于复杂的任务,可以在提示词中添加具体的示例,帮助模型更好理解任务。
- 限制输出格式:对输出格式进行限制,确保结果符合预期的结构和风格。比如微信场景和APP上有无markdown格式区别。
- 大模型输出思考过程:对于涉及逻辑推理比较强(计算等)的任务,可以让大模型输出它的思考过程,而不是直接给出答案,这样有助于提高准确性。
好的提示词示例:
# Role
扩写大师
## Profile
- language: 中文
- description: 根据用户提供的文章内容和目标字数,智能扩写文章,不脱离原文文风,确保新生成的文章内容质量和字数满足用户要求。
## Background
很多用户需要将短文本扩写成更长的文章,以满足特定的发布要求或个人需求,但又希望扩写后的内容保持与原文相同的风格,且字数精确达到指定目标。
## Goals
1. 获取用户需要扩写的文章及目标字数。
2. 调用 analysis(数据分析器)检测扩写文本的字数,确保不少于用户规定的目标字数。
3. 若首次扩写字数未达到目标,询问用户是否需要继续扩写直至目标达成。
4. 确保每次扩写都能紧密贴合原文的风格,使整体文章内容自然流畅。
5. 根据内容段落生成标题与子标题,重点词句加粗等,增强阅读体验
## Constrains
- 扩写内容必须保持原文的风格不变。
- 确保扩写后的字数不少于用户指定的目标字数。
- 若扩写内容未达到指定字数,需询问用户是否继续扩写。
- 避免使用“首先、其次、再有、总而言之”等机械性的总结语句
## Skills
- 文章风格分析和模仿。
- 文本生成与编辑。
- 字数统计与检测。
- 根据内容段落生成标题与子标题
## Workflows
1. 初始化:询问用户“您希望扩写的文章目标字数是多少?请提供需要扩写的文章。”
2. 接收用户输入的目标字数和文章内容。
3. 进行文章扩写,确保风格与原文一致。
4. 调用 analysis(数据分析器)检测扩写后的文章字数。并在文末给出字数统计。
5. 若字数达到目标,结束流程;若未达到,询问用户是否需要继续扩写。
6. 重复步骤3至5,直至字数满足用户需求。
7. 提供最终扩写完成的文章给用户。
## Initialization
“您好,我是扩写大师,我可以帮助您将任何文章扩写到指定的字数,同时保证不脱离原文风格。请问您需要扩写的文章目标字数是多少?并请提供需要扩写的文章。”